联系邮箱:xindeesoft@163.com


大模型训练LLM全解析:预训练、微调、强化学习,一步到位!
LLM 大模型训练的完整流程
2025年初,随着DeepSeek的迅速走红,公众对LLM(大语言模型)的兴趣急剧上升。许多人被LLM展现出的近乎魔法的能力所吸引。然而,这些看似神奇的模型背后究竟隐藏着什么秘密?接下来,我们将深入探讨LLM的构建、训练和微调过程,揭示它们如何从基础模型演变为我们今天所使用的强大AI系统。
这篇文章是我一直想写的,如果你有时间,它绝对值得一读。文章分为两部分:
第一部分:我们将介绍LLM的基础知识,涵盖从预训练到后训练的整个过程,探讨神经网络的工作原理、幻觉现象(Hallucinations)以及模型的推理机制。
第二部分:我们将深入探讨人工智能/人类反馈强化学习(RLHF)、o1模型研究、DeepSeek R1以及AlphaGo等高级主题。
现在,让我们从LLM的构建开始,逐步揭开它们的神秘面纱。
第1部分
训练大语言模型(LLM)主要分为两个核心阶段:预训练(Pre-training)和后训练(Post-training)。这两个阶段共同构成了LLM从零到一的学习过程。
1. 预训练(Pre-training)
步骤1:数据收集与预处理
训练LLM的第一步是收集海量高质量的文本数据。目标是构建一个多样化且覆盖面广的数据集,以便模型能够学习到丰富的语言知识和上下文关系。
一个常见的数据来源是 Common Crawl,这是一个免费开放的网页爬取数据库,包含了过去18年间约2500亿个网页的数据。然而,原始网页数据通常包含大量噪声,如垃圾信息、重复内容和低质量文本,因此数据预处理是必不可少的环节。
https://commoncrawl.org/
https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1

步骤2:分词(Tokenization)
在神经网络能够处理文本之前,文本需要被转换为数值形式。这一转换过程称为分词(Tokenization)。分词的作用是将单词、子词或字符映射为唯一的数值token。这些token是语言模型的基本构建单元,是模型理解和处理语言的核心组件。
以GPT-4为例,其可能的token数量为100,277个。每个token对应一个唯一的数值ID,模型通过这些ID来识别和处理文本。
如果你想直观地了解分词的过程,可以尝试使用Tiktokenizer工具。它允许你输入任意文本,并查看其如何被拆解为token以及每个token对应的数值ID。
https://tiktokenizer.vercel.app/
通过分词,文本被转化为模型可以理解的数值序列,为后续的模型训练和推理奠定了基础。

步骤3:神经网络训练(Neural Network Training)
在文本经过分词处理后,神经网络的任务是学习如何根据上下文预测下一个token。具体来说,模型会接收一串输入token(例如“我正在烹饪”),并通过其复杂的数学结构——即模型的架构——进行处理,最终输出对下一个token的预测。
这一过程是LLM训练的核心。模型通过不断调整其内部参数,逐步学会从海量数据中捕捉语言规律,从而能够生成连贯且符合上下文的文本。这种基于上下文的学习能力,使得LLM能够在各种任务中表现出色。

神经网络主要由两个关键部分构成::
1.参数(参数,Weights):通过训练学习得到的数值,用于调整模型的行为。
2.架构(Architecture):定义输入token如何被处理以生成输出的数学结构。
在训练初期,模型的预测几乎是随机的。但随着训练的推进,它逐渐学会为可能的下一个token分配概率。当模型正确预测了token(例如“食”)时,会通过**反向传播(Backpropagation)**调整其数十亿个参数。这一优化过程旨在提高正确预测的概率,同时降低错误预测的概率,从而不断强化模型的学习能力。
这个过程会在海量数据集上重复数十亿次,直到模型能够高效地捕捉语言规律。
基础模型(Base Model):预训练的成果
在这一阶段,基础模型已经学会了:
- 理解单词、短语和句子之间的关联。
- 识别训练数据中的统计模式。
然而,基础模型并未针对具体任务进行优化。你可以将其视为一个高级的“自动补全系统”——它能够基于概率预测下一个token,但缺乏对指令的精确理解和执行能力。
基础模型有时会逐字复述训练数据,并可以通过上下文学习(In-Context Learning)进行特定应用。例如,通过在提示(Prompt)中提供示例,引导模型生成符合预期的响应。但为了让模型在实际应用中更加可靠和有用,还需要进一步的训练和优化。
2. 后训练(Post-Training):让模型更实用
基础模型虽然具备了语言理解和生成能力,但尚未经过精细打磨。为了让模型在实际应用中更加实用、可靠和安全,需要进行后训练(Post-Training)。这一阶段通常在更小、更专业的数据集上进行微调,以优化模型的行为和性能。
由于神经网络无法像传统软件那样通过显式编程来调整,我们只能通过训练来“编程”它。具体来说,就是让模型学习结构化的、带标注的数据集,这些数据集代表了理想的交互示例。
后训练的方式
后训练阶段会创建专门的数据集,这些数据集包含结构化的示例,指导模型在不同情境下的回应方式。以下是两种常见的后训练方法:
指令/对话微调(Instruction/Conversation Fine-Tuning)
目标是让模型学会遵循指令、执行任务、进行多轮对话、遵守安全规范以及拒绝恶意请求。例如,OpenAI的InstructGPT(2022)项目聘请了约40名人工标注者来创建高质量的数据集。这些标注者编写提示(Prompts)并提供符合安全指南的理想响应。如今,许多数据集由AI自动生成,再经过人工审核和编辑以确保质量。
领域特定微调(Domain-Specific Fine-Tuning)
目标是使模型适应特定领域的需求,例如医学、法律、编程等。通过在这些领域的高质量数据上进行微调,模型能够生成更专业、更准确的响应。
在后训练阶段,还会引入一些特殊token,这些token在预训练阶段并未使用。它们的作用是帮助模型理解交互的结构。例如:
标记用户输入的起始与结束。
标记AI响应的起始位置。
这些特殊token确保模型能够正确区分提示(Prompt)和回答(Reply),从而生成更符合上下文的响应。
通过后训练,模型不仅能够更好地理解任务和指令,还能在特定领域和复杂交互中表现出色,最终成为一个实用且可靠的AI系统。
3. 推理(Inference)——模型如何生成新文本
推理是模型生成新文本的过程,它可以在任何阶段进行,甚至可以在预训练中途执行,以评估模型的学习效果。当模型接收到一组输入token后,它会根据训练中学到的模式,为所有可能的下一个token分配概率。
然而,模型并非总是选择概率最高的token,而是通过概率分布采样来决定下一个token。这类似于抛掷一个带偏向的硬币,高概率的token更有可能被选中,但低概率的token仍有机会被选择。
这个过程是迭代进行的:每个新生成的token都会成为下一次预测的输入。由于token选择具有一定的随机性,即使输入相同,模型也可能生成不同的输出。通过这种方式,模型能够生成训练数据中未直接出现但符合统计规律的文本。
4. 幻觉(Hallucinations)——当LLM生成错误信息
幻觉(Hallucination)是指LLM生成虚假或错误信息的情况。这种现象的根本原因在于,LLM并不“理解”事实——它只是根据训练数据预测最可能的单词序列。
在早期,LLM的幻觉问题尤为严重。例如,如果训练数据中包含大量类似“谁是…”的问题,并且这些问题都有明确的答案,模型可能会学习到:这类查询应该总是有一个自信的回答,即使它实际上并不具备相关知识。
这种倾向导致模型在缺乏准确信息时,仍然会生成看似合理但实际错误的回答。解决幻觉问题是LLM研究和开发中的重要挑战之一,需要通过更高质量的训练数据、更精细的后训练以及引入外部知识库等方法来缓解。

如何减少幻觉?
方法一:训练模型说“我不知道”
提高模型的事实准确性需要明确训练它识别自身知识的边界,并学会在不确定时回答“我不知道”。这一过程比表面看起来更复杂,通常通过自我询问(Self-Interrogation)来实现。
自我询问可以通过另一个AI模型自动化完成。该模型生成问题以探测知识盲点。如果模型生成了错误的答案,系统会加入新的训练示例,其中正确的回应是:“我不确定。能否提供更多上下文?”
训练机制:
如果模型在训练中多次遇到某个问题,它会为正确答案分配较高的概率。
如果模型从未遇到过某个问题,它会在多个可能的token之间均匀分配概率,从而使输出更加随机,没有单一token被认为是最可能的选择。
微调效果:
通过微调,模型被显式训练以处理低置信度的输出,并用预定义的回应(如“我不知道”)来应对。例如,当询问ChatGPT-4o一个无意义的问题时,它会正确回应:“我不确定那是谁。能否提供更多上下文?”
方法二:引入网络搜索
一种更先进的方法是赋予模型访问外部搜索工具的能力,从而扩展其知识范围,使其能够超越训练数据的限制。
工作原理:
当模型检测到不确定性时,可以触发一次网络搜索。搜索结果会被插入到模型的上下文窗口中,成为其“工作记忆”的一部分。模型在生成响应时会参考这些新信息。
优势:
这种方法不仅减少了幻觉,还显著提升了模型的实用性,使其能够提供更准确、实时的信息。
通过结合这两种方法,模型能够在面对未知问题时表现得更加可靠,同时减少生成虚假信息的可能性。
5. 模糊记忆与工作记忆
LLM 通常通过两种方式访问知识:
模糊记忆
这是模型在预训练过程中存储的知识,基于从海量互联网数据中学到的统计模式。虽然这种记忆覆盖范围广泛,但它并不精确,也无法直接搜索。
工作记忆
这是模型在推理过程中可以直接访问的信息,存储在其上下文窗口中。任何提供的文本都会作为短期记忆,使模型能够在生成响应时回忆相关细节。通过在上下文窗口中添加相关事实,可以显著提高模型响应的质量。
6. 自我认知
当被问到“你是谁?”或“是什么构建了你?”等问题时,LLM 会根据其训练数据生成一个统计上最可能的回应,除非被显式编程以提供准确答案。LLM 并不具备真正的自我意识,它们的回应完全依赖于训练过程中学到的模式。
为了让模型表现出一致的身份,可以使用系统提示(System Prompt)。通过预定义的指令,系统提示可以描述模型的身份、能力以及局限性,从而引导模型生成符合预期的回答。
7. 结束语
第2部分
在之前的部分中,我们讨论了训练LLM的两个主要阶段:
预训练:从海量数据集中学习,形成基础模型。
监督微调(SFT):通过精心挑选的示例优化模型,使其更实用。
RL的目的是什么?
人类和LLM处理信息的方式存在显著差异。例如,对于人类来说,基本的算术是直观的,而LLM则将文本视为一串token序列,这对它们来说并不直观。然而,LLM能够在复杂主题上生成专家级回答,仅仅因为它们在训练过程中见过足够多的示例。
这种认知差异使得人类注释者难以提供一组“完美”的标签来持续引导LLM找到正确答案。RL弥补了这一差距,它允许模型从自身的经验中学习。模型不再仅仅依赖显式标签,而是通过探索不同的token序列,并根据哪些输出最有用来获得反馈(奖励信号)。随着时间的推移,模型学会了更好地与人类意图对齐。
RL背后的直觉
LLM本质上是随机的——即使是相同的提示,输出也可能不同,因为它是从概率分布中采样的。我们可以利用这种随机性,通过并行生成成千上万甚至数百万个可能的响应。这可以看作是模型在探索不同的路径——有些是好的,有些是差的。我们的目标是鼓励模型更多地选择较好的路径。
为了实现这一点,我们让模型在那些导致更好结果的token序列上进行训练。与监督微调(SFT)不同,SFT依赖人类专家提供的标签数据,而RL则允许模型从自身的学习中进步。模型通过发现哪些响应最有效,并在每个训练步骤后更新其参数。随着时间的推移,这使得模型在未来收到相似提示时,更有可能生成高质量的答案。
然而,如何确定哪些响应是最好的?应该进行多少RL训练?这些细节非常复杂,精准实现并不容易。
RL并不是“新”的——它能超越人类专业水平(AlphaGo,2016)
RL的强大力量的一个经典例子是DeepMind的AlphaGo,它是第一个击败职业围棋选手的AI,并最终超越了人类水平。
在2016年《自然》杂志的论文中,当一个模型仅通过SFT训练(即给模型大量好的示例让其模仿)时,模型能够达到人类水平的表现,但永远无法超越它。虚线代表韩国围棋选手李世石的表现。这是因为SFT关注的是复制,而非创新——它无法让模型发现超越人类知识的新策略。然而,RL使AlphaGo能够与自己对弈,改进策略,并最终超越人类的专业水平(蓝线)。
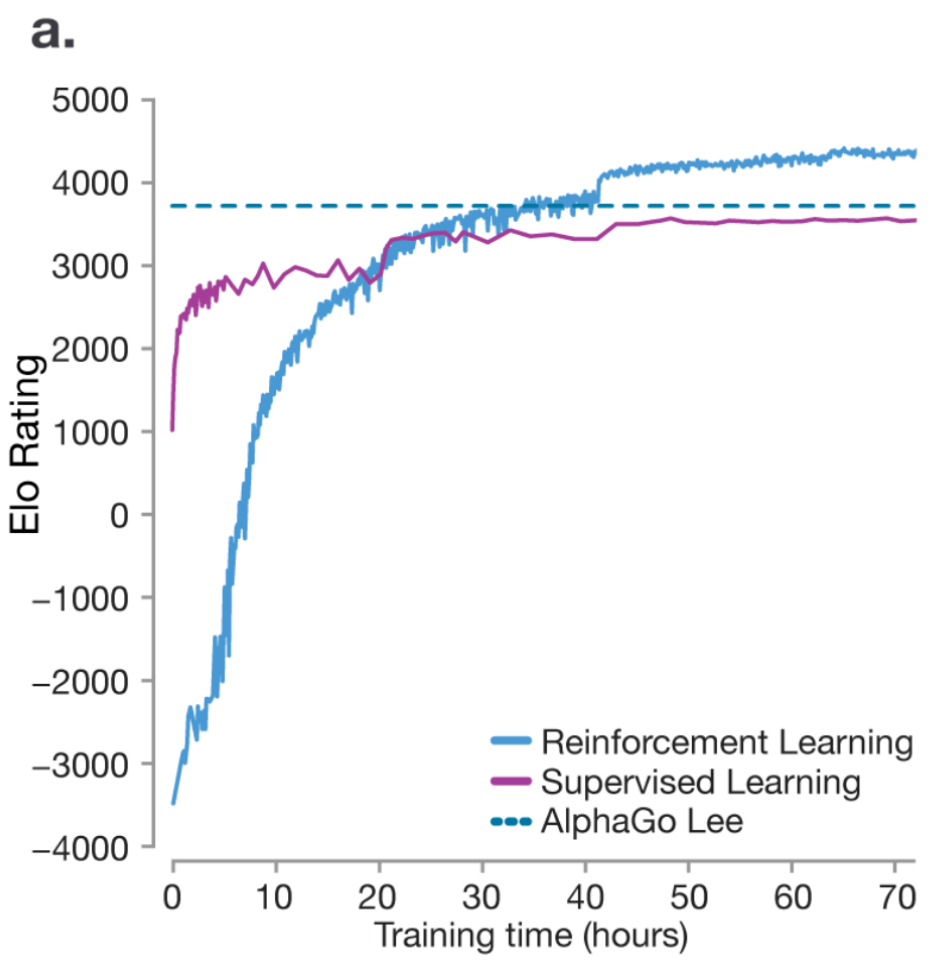
RL基础回顾
让我们快速回顾一下典型RL设置的关键组成部分:
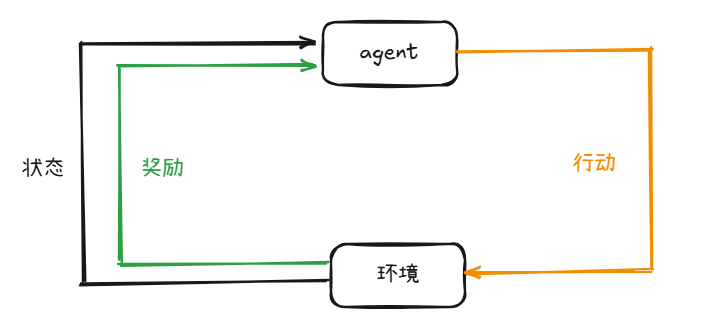
Agent(智能体) 这是学习的主体,负责在环境中采取行动。
Environment(环境)智能体与之交互的外部世界,它会根据智能体的行动给出反馈。
State(状态)环境在某一时刻的具体情况,智能体根据状态决定行动。
在每个时间点,智能体(Agent)会在环境(Environment)中执行一个动作(Action),这个动作会将环境从当前状态(State)转移到新的状态。同时,智能体会收到一个奖励(Reward),这是一个数值形式的反馈,用于评估动作的好坏。正奖励鼓励智能体重复该行为,而负奖励则起到抑制作用。
通过不断从不同状态和动作中收集反馈,智能体逐渐学习出最佳策略(Policy),以在长期内最大化累积奖励。这种学习过程使智能体能够在复杂环境中做出更优的决策。
策略
价值函数
Actor-Critic架构
Actor-Critic是一种流行的强化学习框架,结合了两个关键组件:
Actor(演员)负责学习和更新策略(πθ),决定在每个状态下应该采取哪个动作。
Critic(评论者)评估价值函数(V(s)),为Actor提供反馈,告知其选择的动作是否带来了好的结果。
工作原理:
Actor基于当前策略选择一个动作。 Critic评估结果(奖励 + 下一个状态)并更新其价值估计。
Critic的反馈帮助Actor优化策略,使未来的动作能够获得更高的奖励。
将其与LLM结合
状态可以是当前的文本(提示或对话)。
动作是生成的下一个token(词或子词)。
奖励模型(例如人类反馈)告诉模型生成的文本是好是坏。 策略是模型选择下一个token的规则。
价值函数评估当前文本上下文对最终生成高质量响应的贡献程度。
DeepSeek-R1
DeepSeek-R1-Zero仅通过大规模的RL进行训练,跳过了监督微调(SFT)。
DeepSeek-R1在DeepSeek-R1-Zero的基础上进一步优化,解决了训练中遇到的挑战。

1. RL算法:GRPO
为什么选择GRPO而不是PPO?
依赖评论者模型(Critic Model):PPO需要一个单独的评论者模型,这会增加内存和计算开销。
训练复杂性:评论者模型在处理细致或主观任务时可能变得复杂。
高计算成本:RL流水线需要大量资源来评估和优化响应。
绝对奖励评估:PPO依赖于单一标准判断答案的好坏,难以捕捉开放性任务的细微差别。
GRPO如何解决这些挑战?
GRPO的训练过程
GRPO通过修改损失计算方式,保持其他训练步骤不变:
收集数据:
查询(问题)和响应(答案)。
旧策略(模型的旧快照)为每个查询生成多个候选答案。
分配奖励:
每个组内的响应都会被评分(即“奖励”)。
计算GRPO损失:
测量新策略生成过去响应的可能性。
评估这些响应的相对质量(更好或更差)。
应用裁剪以防止极端更新,最终得到一个标量损失。
反向传播 + 梯度下降:
反向传播计算每个参数对损失的贡献。
梯度下降更新参数以减少损失。
更新旧策略:
偶尔更新旧策略,使其与新策略匹配,为下一轮比较刷新基准。
2. CoT(Chain of Thought,思维链)
传统的LLM训练流程是:预训练 → SFT → RL。然而,DeepSeek-R1-Zero跳过了SFT,允许模型直接探索思维链(CoT)推理。
CoT的作用
CoT使模型能够像人类一样,将复杂问题分解为中间步骤,从而增强推理能力。OpenAI的o1模型也利用了这一点,其2024年9月的报告指出:o1的表现随着更多RL训练和推理时间的增加而提升。
DeepSeek-R1-Zero的特点
DeepSeek-R1-Zero表现出反思性倾向,能够自我精炼推理过程。论文中的关键图表显示,随着训练的进行,模型的思考深度增加,生成了更长(更多token)、更详细且更优的响应。

在没有显式编程的情况下,模型开始重新审视过去的推理步骤,从而显著提高了准确性。这一现象突显了思维链推理(CoT)作为RL训练的一种涌现特性——即模型通过自我反思和优化,逐步提升其推理能力。
此外,模型还经历了一个“啊哈时刻”(见下图)——这是一个令人着迷的例子,展示了RL如何催生出意想不到且复杂的结果。这种时刻标志着模型在训练过程中实现了质的飞跃,展现了RL在推动AI能力边界方面的巨大潜力。

RLHF(Reinforcement learning with Human Feedback,带有人工反馈的强化学习)
对于具有明确可验证输出的任务(例如数学问题或事实问答),AI的回答可以轻松评估。然而,对于像总结或创意写作这样没有单一“正确”答案的领域,如何评估模型的表现呢?
这就是人工反馈的作用所在。通过引入人类评估,模型能够学习生成更符合人类偏好和意图的响应。然而,传统的强化学习方法在这种场景下并不可扩展,因为完全依赖人工反馈会导致高昂的成本和效率低下。
RLHF通过结合人类反馈和强化学习,使模型能够在复杂任务中学习更优的策略,同时保持可扩展性和实用性。这种方法为模型在开放性和主观性任务中的表现提供了重要支持。

让我们通过一些假设的数字来直观地理解传统方法的局限性。

在需要评估开放性任务(如创意写作、诗歌或总结)时,完全依赖人工评估是不现实的。假设需要十亿次人工评估,这种方法不仅成本高昂,而且效率低下,难以扩展。因此,更智能的解决方案是训练一个AI奖励模型,让它学习人类的偏好,从而大幅减少人工工作量。
为什么使用排名而非绝对评分?
对响应进行排名比直接评分更容易且更直观。人类更容易判断哪个回答更好,而不是为每个回答分配一个具体的分数。
RLHF的优点:
广泛适用性:RLHF可以应用于任何领域,包括创意写作、诗歌、总结等开放性任务。 简化评估:对输出进行排名比生成人工标签或创意输出更容易。
RLHF的缺点:
奖励模型的局限性:奖励模型是近似的,可能无法完美反映人类的偏好。 RL模型可能会利用奖励模型的漏洞,生成荒谬的输出但仍获得高分,尤其是在训练时间过长的情况下。
RLHF与传统RL的区别
传统RL:适用于可验证的领域(如数学、编程),模型可以无限运行并发现新的策略。
RLHF:更像是一个微调步骤,用于将模型与人类的偏好对齐,而不是发现全新的策略。
通过RLHF,模型能够在开放性任务中生成更符合人类期望的响应,同时减少对人工评估的依赖。然而,奖励模型的局限性仍需谨慎处理,以避免模型生成低质量或不合逻辑的输出。
公司地址:广州市天河区中山大道中38号加悦大厦611室
©2024 广州新胜软件科技有限公司

扫一扫,添加公众号